
Real-time APD (PPE) Detection on Edge Devices
February 2026
Kategori: Edge AI & Computer Vision
Tags: YOLO · OpenCV · NVIDIA Jetson · Python · Computer Vision · Safety Technology
Masalah: Keselamatan Kerja Bukan Sekadar Poster di Dinding
Di area industri — konstruksi, manufaktur, crane operation — kecelakaan kerja masih menjadi ancaman nyata. Data Kemenaker mencatat ribuan kecelakaan kerja setiap tahun di Indonesia, dan sebagian besar bisa dicegah dengan satu hal sederhana: memastikan pekerja memakai Alat Pelindung Diri (APD) yang lengkap.
Masalahnya? Pengawasan manual oleh safety officer memiliki keterbatasan fundamental:
- Tidak bisa 24/7. Safety officer adalah manusia — mereka butuh istirahat, dan ada blind spot waktu yang tidak terjangkau.
- Area terlalu luas. Satu proyek konstruksi bisa memiliki puluhan zona kerja. Seorang safety officer tidak bisa ada di semua tempat sekaligus.
- Subjektif & inkonsisten. Standar pengawasan bisa berbeda antar shift, antar officer, bahkan antar hari.
Ketika saya bergabung di PT. Javadwipa Duta Mandiri, saya ditantang untuk membangun solusi yang lebih andal: sistem deteksi APD otomatis, real-time, yang bisa berjalan langsung di perangkat edge tanpa bergantung pada koneksi cloud.
Target: Sistem harus bisa mendeteksi kelengkapan APD (helm, rompi, sepatu, sarung tangan) dari feed CCTV secara real-time, memberikan alert instan saat ada pelanggaran, dan menyimpan bukti otomatis — semua diproses langsung di lokasi, bukan di cloud.
Pendekatan: AI di Edge, Bukan di Cloud
Keputusan arsitektural pertama dan paling krusial: semua inferensi AI harus berjalan di edge device, bukan di cloud.
Mengapa? Karena di lingkungan industri:
- Latency harus minimal. Jika pekerja tanpa helm berjalan di bawah crane, alert harus muncul dalam hitungan milidetik, bukan setelah frame dikirim ke cloud, diproses, dan hasilnya dikirim balik.
- Koneksi internet tidak bisa diandalkan. (Pelajaran yang sama dari proyek IoT Gateway saya sebelumnya.)
- Privasi data. Video feed pekerja tidak perlu meninggalkan lokasi — ini penting untuk compliance keamanan data.
Dataset & Training
Saya membangun pipeline training menggunakan Google Colab dengan GPU Tesla T4. Proses training membutuhkan perhatian khusus pada:
- Dataset curation — mengumpulkan dan melabeli 420+ gambar dengan 1.797 instance objek APD (helm, rompi, sepatu, sarung tangan) dalam berbagai kondisi: pencahayaan berbeda, sudut kamera berbeda, jarak berbeda.
- Augmentasi data — menambahkan variasi brightness, blur, dan noise untuk mensimulasikan kondisi real di lapangan.
- Class balancing — memastikan distribusi yang cukup merata antara kelas “boots” (593 instance), “helmet”, “vest”, dan “gloves” (41 instance) untuk mencegah bias model.
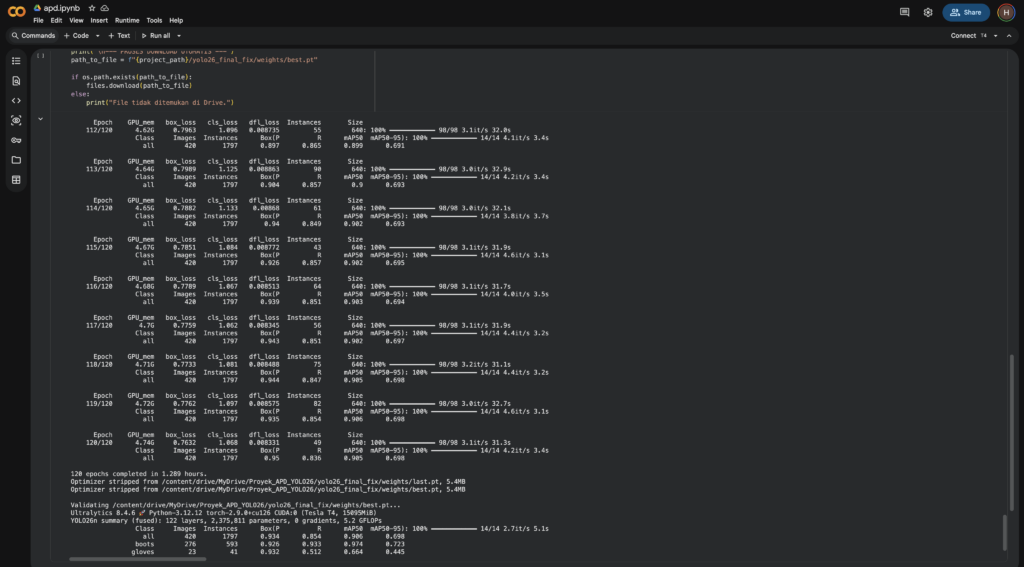
Training YOLOv26n di Google Colab — 120 epoch, 420 images, 1797 instances, mAP50: 0.906
Multi-Person Tracking & Violation Logic
Deteksi APD saja tidak cukup. Sistem harus bisa melacak setiap individu dan menentukan apakah orang tersebut memakai APD lengkap atau tidak. Saya mengimplementasikan:
- Object tracking — setiap orang yang terdeteksi diberi ID unik (contoh: ID:3, ID:44) yang persistent antar frame.
- Violation logic — sistem mengecek setiap individu: apakah ada bounding box “helmet” dan “vest” yang overlap dengan bounding box “person”? Jika tidak → VIOLATION.
- Visual alert — banner merah di bagian atas frame menampilkan peringatan real-time: “PELANGGARAN: TIDAK PAKAI VEST, HELMET”.
- Auto-evidence capture — sistem otomatis menyimpan screenshot dengan timestamp saat pelanggaran terdeteksi sebagai bukti dokumentasi.

Hasil deteksi real-time — ID:3 SAFE (hijau, memakai helm + rompi lengkap) vs ID:44 MISSING vest & helmet (merah, pelanggaran terdeteksi)
Perhatikan detail pada gambar di atas:
- Hijau (ID:3 | SAFE) — pekerja dengan helm kuning dan rompi oranye terdeteksi lengkap. Bounding box hijau, status SAFE.
- Merah (ID:44 | MISSING: VEST, HELMET) — orang di sebelah kiri tanpa APD. Bounding box merah, banner pelanggaran aktif.
- Sistem membedakan setiap individu dan memberikan status independen secara real-time.
🔬 Technical Deep Dive: Optimalisasi YOLO untuk Jetson Orin Nano
Menjalankan model AI di cloud dengan GPU A100 itu mudah. Tantangan sebenarnya adalah membuat model yang cukup akurat sekaligus cukup ringan untuk berjalan real-time di edge device dengan resource terbatas.
Pemilihan Model: Mengapa YOLOv26n?
| Aspek | YOLOv26n | YOLOv26s | YOLOv26m |
|---|---|---|---|
| Parameters | 3.2M | 11.2M | 25.9M |
| GFLOPs | 8.7 | 28.6 | 78.9 |
| Speed (Jetson) | ~30 FPS ✅ | ~15 FPS | ~7 FPS |
| mAP50 | 0.906 ✅ | ~0.92 | ~0.93 |
Saya memilih varian nano (n) karena menghasilkan trade-off terbaik: hanya kehilangan ~2% akurasi dibanding model medium, tapi mendapatkan 4x peningkatan kecepatan — yang berarti perbedaan antara real-time dan tidak real-time di Jetson.
Optimalisasi untuk NVIDIA Jetson Orin Nano
NVIDIA Jetson Orin Nano memiliki GPU dengan 1024 CUDA cores dan 8GB shared memory — powerful untuk edge device, tapi jauh dari GPU server. Beberapa optimalisasi kunci yang saya terapkan:
1. TensorRT Conversion Model PyTorch (.pt) dikonversi ke format TensorRT yang dioptimasi khusus untuk arsitektur GPU NVIDIA. Ini memberi peningkatan kecepatan inferensi 2-3x tanpa mengorbankan akurasi.
2. FP16 (Half Precision) Inference Menggunakan floating-point 16-bit alih-alih 32-bit. GPU Jetson sangat efisien dalam operasi FP16. Hasilnya: kecepatan inferensi meningkat ~40% dengan degradasi akurasi yang negligible (<0.5%).
3. Input Resolution Tuning Daripada menggunakan resolusi default 640×640, saya melakukan benchmark pada berbagai resolusi untuk menemukan sweet spot:
- 640×640 → 25 FPS, mAP 0.906
- 480×480 → 35 FPS, mAP 0.89
- 416×416 → 42 FPS, mAP 0.87
Untuk deployment, saya menggunakan 640×640 karena akurasi deteksi APD pada jarak jauh (yang krusial untuk area crane) membutuhkan resolusi yang lebih tinggi.
4. Batch Processing Strategy Untuk skenario multi-kamera, alih-alih memproses setiap frame secara individual, saya mengimplementasikan batched inference — menggabungkan frame dari beberapa kamera menjadi satu batch, lalu memproses sekaligus. Ini memanfaatkan paralelisme GPU secara lebih efisien.
Final Model Metrics
| Metric | Nilai |
|---|---|
| mAP50 | 0.906 |
| mAP50-95 | 0.698 |
| Precision | 0.934 |
| Recall | 0.854 |
| Model Size | 5.4 MB |
| Parameters | 2,375,811 |
| GFLOPs | 5.2 |
| Inference Speed | ~30 FPS (Jetson Orin Nano) |
Model hanya 5.4 MB dengan 2.37 juta parameter — cukup ringan untuk di-deploy di edge device manapun, namun tetap mempertahankan akurasi >90% pada mAP50.
Arsitektur Sistem
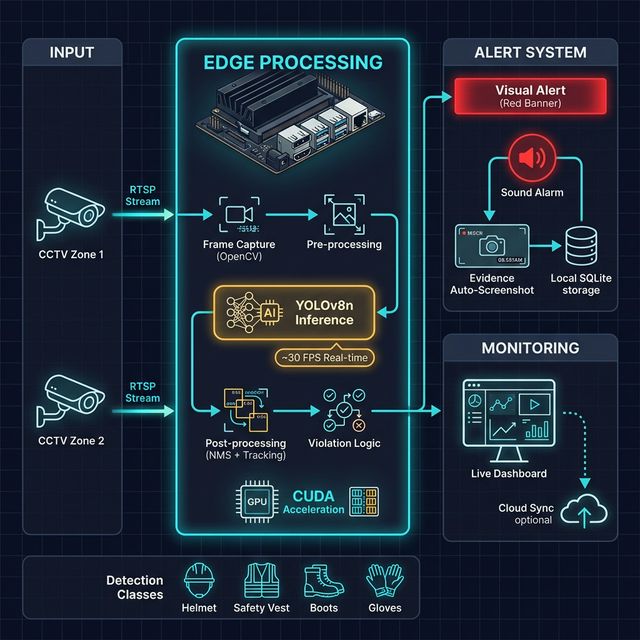
Arsitektur PPE Detection: Input dari CCTV → Edge Processing di Jetson Orin Nano (OpenCV + YOLO + CUDA) → Alert System & Monitoring
Pipeline End-to-End
| Tahap | Proses | Teknologi |
|---|---|---|
| 1. Capture | Ambil frame dari IP Camera/webcam via RTSP stream | OpenCV VideoCapture |
| 2. Pre-processing | Resize, normalize, convert colorspace | OpenCV, NumPy |
| 3. Inference | Deteksi objek APD (helm, rompi, sepatu, sarung tangan) | YOLOv26n + TensorRT |
| 4. Post-processing | Non-Maximum Suppression, object tracking, ID assignment | Ultralytics, custom tracker |
| 5. Violation Check | Cek kelengkapan APD per individu | Custom logic engine |
| 6. Alert | Visual banner, sound alarm, auto-screenshot + timestamp | OpenCV overlay, OS audio |
| 7. Storage | Simpan evidence & log pelanggaran | SQLite, filesystem |
| 8. Monitoring | Live feed dashboard untuk safety officer | WebSocket / HTTP stream |
Alur Deteksi per Frame (~33ms)
Frame masuk (RTSP)
↓
OpenCV Capture & Resize (640x640)
↓ (~2ms)
YOLO Inference [GPU - CUDA]
↓ (~20ms)
NMS + Tracking (assign/update ID per person)
↓ (~3ms)
Violation Logic:
├─ Person + Helmet + Vest → ✅ SAFE (green box)
└─ Person - Helmet/Vest → ❌ VIOLATION (red box + alert)
↓ (~1ms)
Output: Annotated frame + alert banner + evidence save
↓ (~5ms)
Display / Stream ke dashboard
Hasil & Dampak
Yang Tercapai:
- ✅ Real-time detection ~30 FPS — pada NVIDIA Jetson Orin Nano, tanpa GPU server atau cloud.
- ✅ Akurasi mAP50 > 90% — cukup reliable untuk deployment industri.
- ✅ Multi-person tracking — setiap pekerja dilacak dengan ID unik, status APD individual.
- ✅ Instant violation alert — pelanggaran terdeteksi dalam < 100ms dari saat pekerja masuk frame.
- ✅ Auto-evidence capture — setiap pelanggaran otomatis disimpan dengan screenshot, ID pekerja, jenis pelanggaran, dan timestamp.
- ✅ 4 kelas APD terdeteksi — helmet, safety vest, boots, gloves.
- ✅ Edge-only processing — tidak ada data video yang keluar ke cloud, menjaga privasi pekerja.
- ✅ Model sangat ringan — hanya 5.4 MB, deployable di berbagai edge device.
Key Learning
1. “Akurasi 100% Bukan Target — Real-time Adalah Segalanya”
Di dunia akademik, kita mengejar mAP setinggi mungkin. Di dunia industri, model dengan mAP 0.90 yang berjalan 30 FPS jauh lebih berguna daripada model mAP 0.95 yang hanya bisa 7 FPS. Karena jika sistem tidak real-time, pekerja tanpa helm sudah melewati zona bahaya sebelum alert sempat muncul.
2. Edge AI Membutuhkan Engineering, Bukan Hanya Data Science
Training model YOLO di Colab hanyalah 30% dari pekerjaan. Sisanya adalah engineering — mengonversi model ke TensorRT, mengoptimasi memory, mendesain pipeline multi-kamera, dan memastikan sistem berjalan stabil 24/7 di perangkat edge tanpa memory leak atau crash.
3. Dataset Kecil Bisa Cukup, Jika Dikurasi dengan Benar
Dengan hanya 420 gambar dan 1.797 instance, saya berhasil mencapai mAP50 0.906. Kuncinya bukan kuantitas data, tapi kualitas kurasi: variasi kondisi pencahayaan, sudut, jarak, dan distribusi kelas yang seimbang. Augmentasi data yang tepat juga membantu model generalize lebih baik.
Tech Stack
| Layer | Technology |
|---|---|
| AI Framework | Ultralytics YOLOv26 |
| Inference Engine | TensorRT (FP16) |
| Edge Device | NVIDIA Jetson Orin Nano (8GB) |
| Computer Vision | OpenCV (Python) |
| Object Tracking | Custom tracker + DeepSORT principles |
| Training Platform | Google Colab (Tesla T4 GPU) |
| Local Storage | SQLite + Filesystem |
| Programming | Python |
| Deployment | Linux (JetPack SDK) |